First, that's only on OS X, sorry for folks running it on a different platform. Second, it's a bit of a lie, as I am talking about bug 448003.
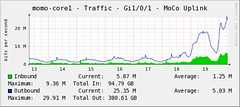
Since we switched over to building from Mercurial, the code size tests we run were somewhat off on OS X. These tests basically measure the size of the code included in the product. For instance, right now, on Linux, it's reported at 15.7MB.
However, on OS X, they had been reporting 1.56GB! Obviously, this was a bug somewhere in the computation of this number, not the actual code size, so that's why the subject of this post is appropriately misleading.

Various hypothesis were put forward, including the fact it looked like it was off by precisely 100, so possibly a unit conversion problem, or something similar.
I've finally gotten around to it, and after some investigation, turns out it's more interesting than that. On OS X, we don't directly build universal binaries, but instead build once for i386 and once for ppc, then lipo the 2 builds together to form the final product.
To determine code size in this case, it would be misleading to count both architectures, so instead we pick one and size up that one. In our case, for historical reasons, that's the ppc version, even though our build boxes are Intel by now. Determining code size is done by parsing the output of /usr/bin/nm, an object dumping tool that nicely dumps the symbols list out of libraries and executables. Unfortunately, it dumps positions in the code, not size. So, to determine code size for a given function, just make sure addresses are sorted, then subtract the address of the previous function to the address of the current function, and you'll get the number of bytes that it takes up in the object file. Simple, right ?
Well, for some reason, not yet explained, on ppc, there is a strange symbol called trampoline_size that exists first in the list of symbols and sits at address '0'. However, right after it is the next symbol, strangely sitting at the address 0x20000000. That's 536870912 bytes further, if we believe what this is telling us. Of course, this is bogus. I am not entirely certain what this about, but if I could venture a guess, I'd have to say it has to do with the ppc executable format, OS X, and their ability to transparently run ppc binaries on Intel. Anybody that knows OS X/PPC better than me, feel free to correct me on this.
libnspr4.dylib: 00000028 a trampoline_size
libnspr4.dylib: 20000000 t __mh_dylib_header
libnspr4.dylib: 20001a7c t dyld_stub_binding_helper
Now that the problem is somewhat understood, it was a simple matter of teaching the code size stuff to ignore symbols like that on OSX/ppc and start at the next one. As you can see from the Tinderbox boxes, it was still pretty impressive to see such a large code size decrease! Oh, and SeaMonkey got the same drop in size, for the same reason.
]]>